KeyGNet (Learning better keypoints)
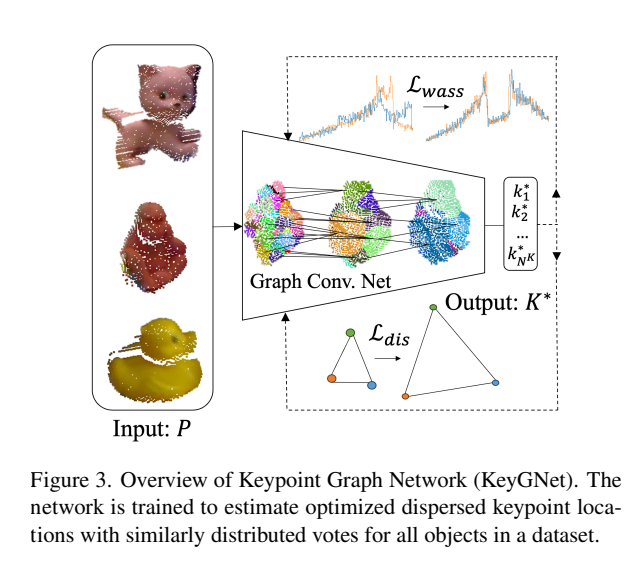
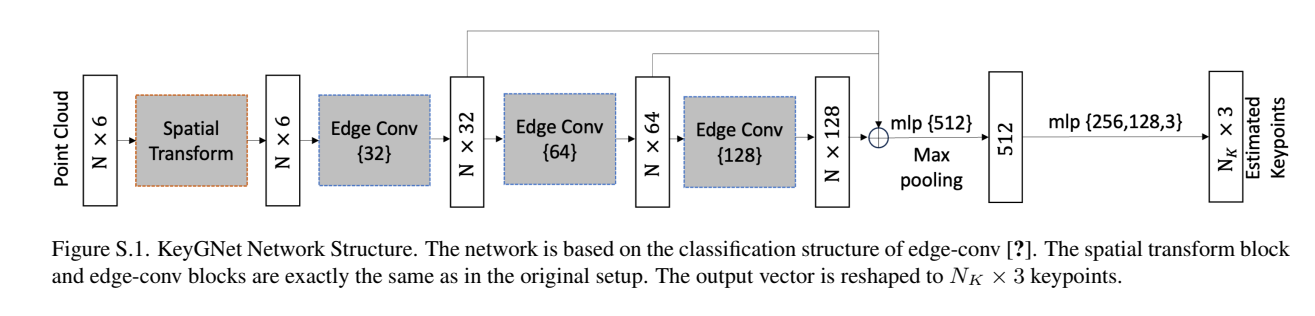
Overview
This addresses the issue of keypoint selection, by creating an optimal selection.
End-to-end
Input: point cloud representing
- Spatial Transform
- Input point cloud through spatial transform, this normalizes the data in a canonical way so that we define all our input in the same “orientation”.
- Edge conv:
- Run transformed data through three edge convolutions. These operate on the edges connecting the points in our data. This updates the features of each point w.r.t. the neighbouring points.
- Output:
- Outputs a vector which represent the keypoints we’re predicting.
- Loss!
- We use Wasserstein loss, , because it:
- Is more robust to small changes in the input
- Good for keypoint prediction as even when two compared distributions don’t overlap it still provides a good estimation.
- Here we apply gradient penalty to make predictions similar to each other rather than the ground truth.
- We use dispersion loss to:
- Make sure keypoints are well-dispersed
- Final loss:
- We use Wasserstein loss, , because it: