Suppose we have a sequence of RVsX1,…,Xn which have the same marginal distribution. If we perform sample-by-sample scalar quantization, this yields the average MSE E[n1i=1∑n(Xi−Q(Xi))2]=E[(Xi−Q(Xi))2]We observe that distortion stays the same whether or not our Xi’s have any interdependence. So since we aren’t exploiting the statistical interdependence between RVs we aren’t squeezing out the most out of our quantization that we should be.
Idea
To exploit the statistical interdependence we can form a linear prediction, X^n, from the previous m samples X~n=i=1∑maiXn−iand quantize the difference signalen=Xn−X~n=Xn−a1Xn−1−⋯−amXn−m
Definition (FIR Filter)
A finite impulse response (FIR) filter is a filter whose impulse response is of finite duration. We define its transfer function as P(z)=i=1∑maiz−i
Let P be the FIR Filter with transfer function P(z)=i=1∑maiz−iWithout quantization the Xn can be perfectly reconstructed:
Pasted image 20240312114126.png
We see that since en is less spread out in its output that it is easier to quantize. Adding quantization to the mix we now have our proposed scheme:
We see if quantization error is small then en≈e^n⟹X^n≈Xn. But in this structure we see the error accumulates.
Let hn denote the impulse response of the transfer function1−P(z)1, also let X^n=e^n∗hn, Xn=en∗hn, and Xn−X^n=(en−e^n)∗hn. Hence, E[(Xn−X^n)2]=E[((en−e^n)∗hn)2]=E(i=0∑nen−i−Q(en−i)(en−i−e^n−i)∗hi)2en−i−Q(en−i)(en−i−e^n−i)We see that at time n we depend on all past quantization errors ei−Q(ei)! This means all our errors accumulate. We need a different structure, which brings us to Difference Quantization.
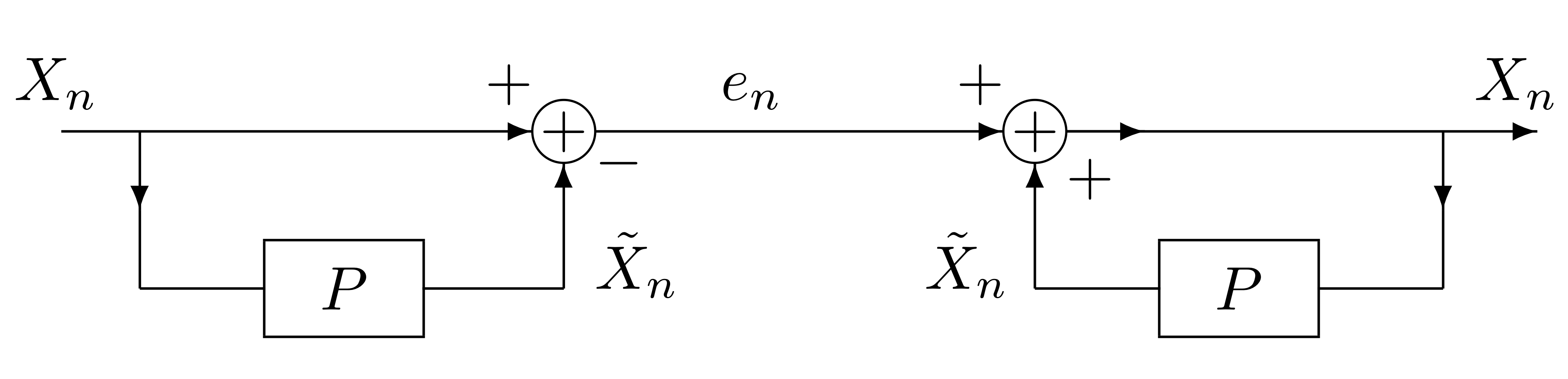
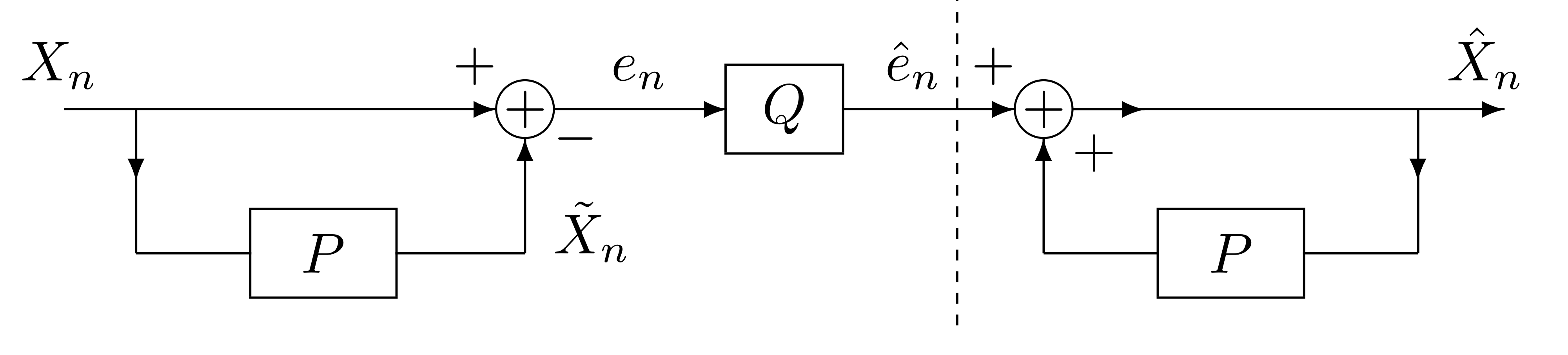 We see if quantization error is small then . But in this structure we see the error accumulates.
We see if quantization error is small then . But in this structure we see the error accumulates.